Z06-03 专题-AIAgent-N8N
[TOC]
N8N 介绍
==n8n==:是一款开源低代码工作流自动化平台,由德国开发者 Jan Oberhauser 于 2019 年创立,总部位于柏林。它通过可视化节点连接方式,让用户无需编写大量代码即可构建复杂的自动化流程,同时保留了代码级灵活性。
部署
本地部署
Node部署
npx n8nDocker部署
Docker 部署:
创建卷:
shdocker volume create n8n_datadocker 部署 n8n:
shdocker run -it --rm \ --name n8n \ -p 5678:5678 \ -v n8n_data:/home/node/.n8n \\ -v D:/Docker/Download:/home/node/.n8n \ docker.n8n.io/n8nio/n8n-it:交互模式--rm:docker 退出运行后自动删除镜像--name n8n:docker 容器名称-p 5678:5678:端口映射(外部端口 : docker内部端口)-v n8n_data:/home/node/.n8n:数据存储映射(外部路径 : docker内部路径)docker.n8n.io/n8nio/n8n:镜像地址
==报错==:端口占用:
docker: Error response from daemon: ports are not available: exposing port TCP 0.0.0.0:5678 -> 127.0.0.1:0: listen tcp 0.0.0.0:5678: bind: An attempt was made to access a socket in a way forbidden by its access permissions.原因分析:
这个错误表明 Docker 无法在主机上绑定 5678 端口,因为该端口已被其他程序占用,或者被系统策略/防火墙阻止。
解决:在 CMD 窗口中执行以下命令:
查看5678是否被占用:
shnetstat -ano | findstr :5678 # 结果显示没有被占用查看5678是否在windows系统的保留端口中:
shnetsh interface ipv4 show excludedportrange protocol=tcp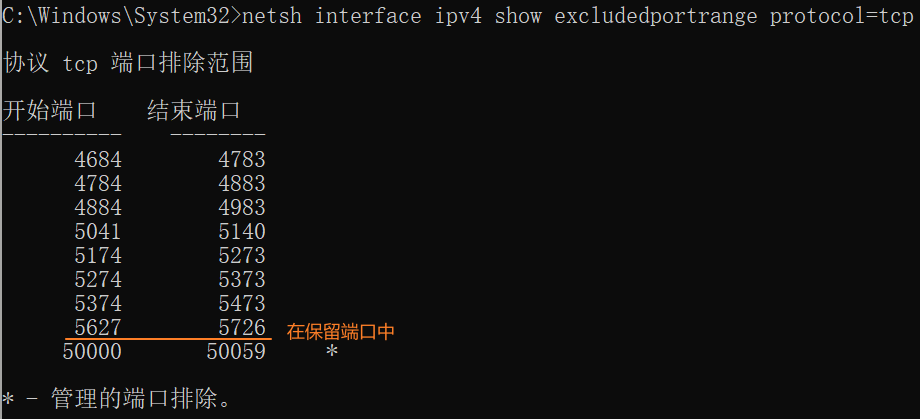
修改docker中n8n的端口:既然在系统保留端口中,我们可以修改docker中n8n的端口
shdocker run -it --rm \ --name n8n \ -p 15678:5678 \ -v n8n_data:/home/node/.n8n \ docker.n8n.io/n8nio/n8n
线上部署【
HuggingFace
注册:
Supabase
注册:
创建 Group:
实战:新闻订阅
新闻订阅:每天早8点,自动抓取国外AI新闻,经过AI翻译整理,自动发送到Telegram的指定频道。
添加
Schedule Trigger: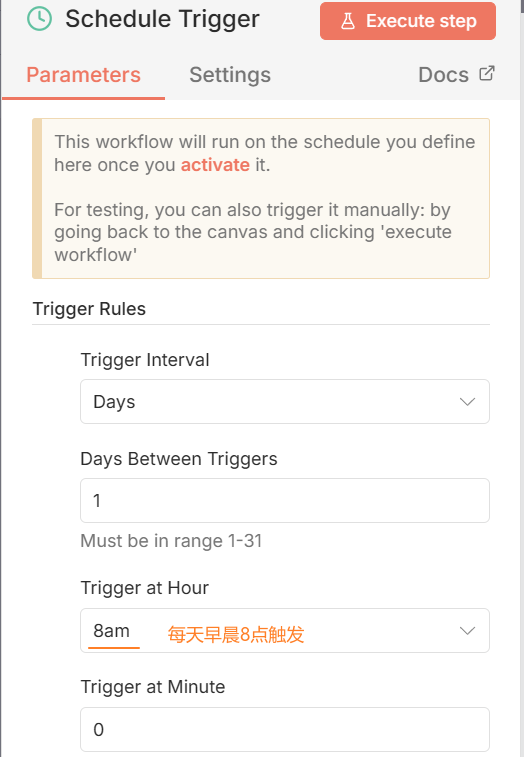
问题:时区不对:默认时区是美国纽约时间,需要修改成北京时间

修改成上海时间:
Settins - Timezone
实战:RAG
RAG 介绍
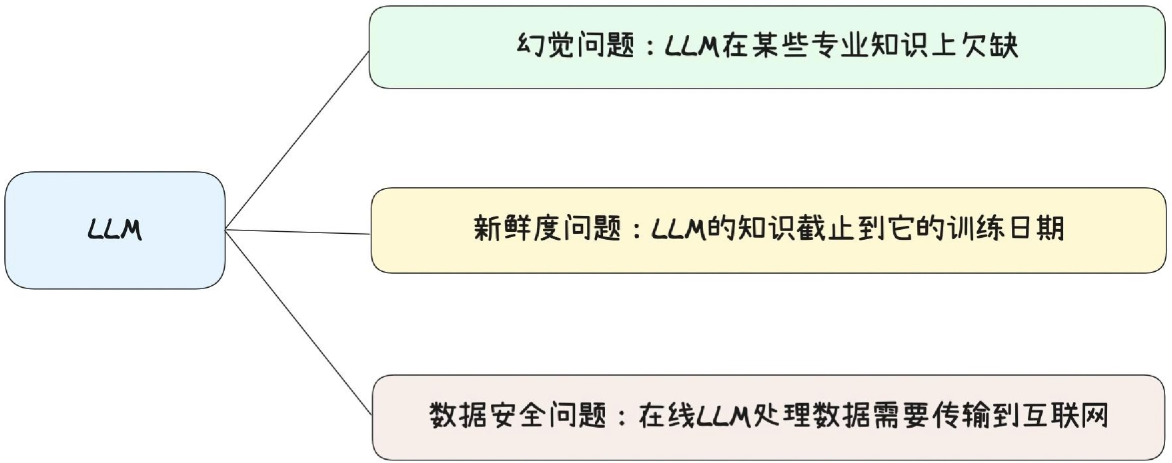
==RAG(Retrieval-Augmented Generation,检索增强生成)==:是一种结合信息检索与生成式 AI的技术架构,核心目标是解决大语言模型(LLM)的两大痛点:知识时效性不足和幻觉问题。
RAG 工作流程:
RAG 的工作流程可以拆解为 3 个核心阶段,本质是 “先找答案依据,再生成答案”,而非让大模型凭空 “回忆”。
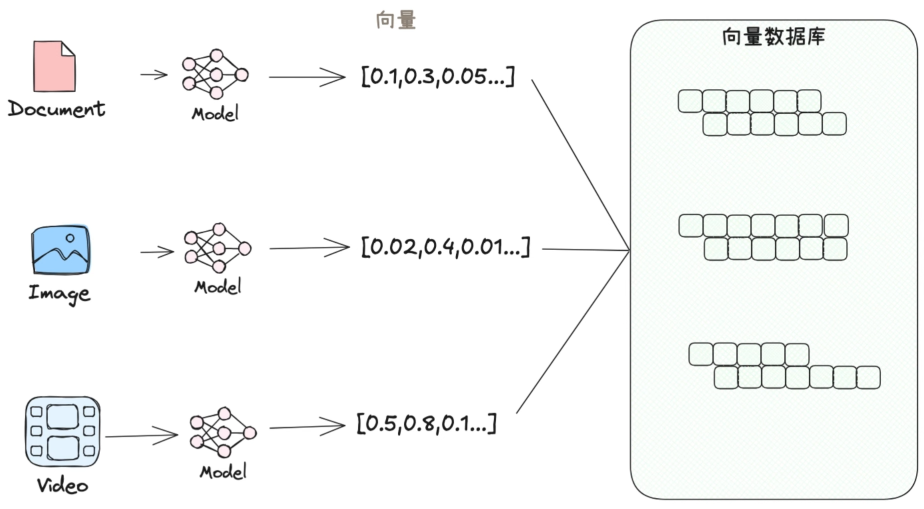
数据预处理与存储(离线阶段)
- 文档加载:导入私有数据、最新文档或特定知识库(如 PDF、文档、数据库记录、API 数据等)。
- 文本分割:将长文档切分为小片段(Chunk),避免超出 LLM 上下文窗口,同时保证片段语义完整。
- 向量化编码:通过嵌入模型(Embedding Model) 将文本片段转换为高维向量(Embedding),向量的相似度对应文本内容的相似度。
- 向量存储:将向量数据存入向量数据库(如 Pinecone、Milvus、FAISS),方便后续快速检索。
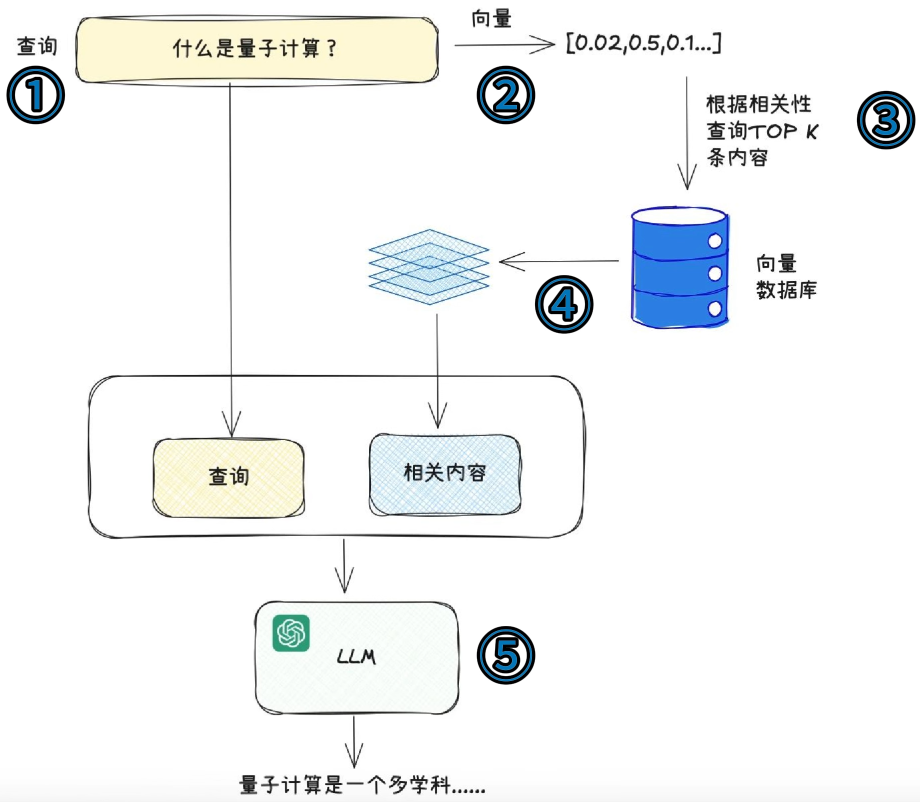
检索阶段(在线查询阶段)
- 用户输入查询问题后,先将问题同样转换为向量。
- 向量数据库根据相似度算法(如余弦相似度),从库中检索出与问题最相关的 Top-K 个文本片段(即 “证据”)。
- 这个过程类似搜索引擎,区别是基于语义而非关键词匹配。
生成阶段(答案生成阶段)
- 将用户问题 + 检索到的文本片段拼接成一个提示词(Prompt),发送给大语言模型。
- 大语言模型基于提示词中的 “证据” 生成答案,确保输出内容有依据、不跑偏。
RAG 的核心优势:
降低幻觉风险:
生成式 AI 容易编造不存在的信息(幻觉),RAG 让模型 “有据可依”,输、出内容的准确性和可信度大幅提升。
解决知识滞后问题:
大语言模型的训练数据有时间截止点(如 GPT-4 截止到 2023 年),无法回答最新事件或私有数据。RAG 可直接引入实时 / 私有数据,无需重新训练大模型。
支持私有数据安全使用:
敏感数据(如企业内部文档、客户数据)无需上传到公有大模型平台,可通过本地部署的向量数据库 + 私有化 LLM 实现数据隔离,满足合规要求。
成本更低,灵活性更高:
相比 微调(Fine-tuning) 大模型,RAG 无需消耗大量计算资源训练模型,只需更新向量数据库中的数据,即可快速迭代知识库。
RAG系统搭建
搭建知识库
方式一:上传本地文件
搭建知识库:
思路:将本地的 PDF/MD/CSV 等文件上传后经过大模型解析后保存到 pinecone 向量数据库中
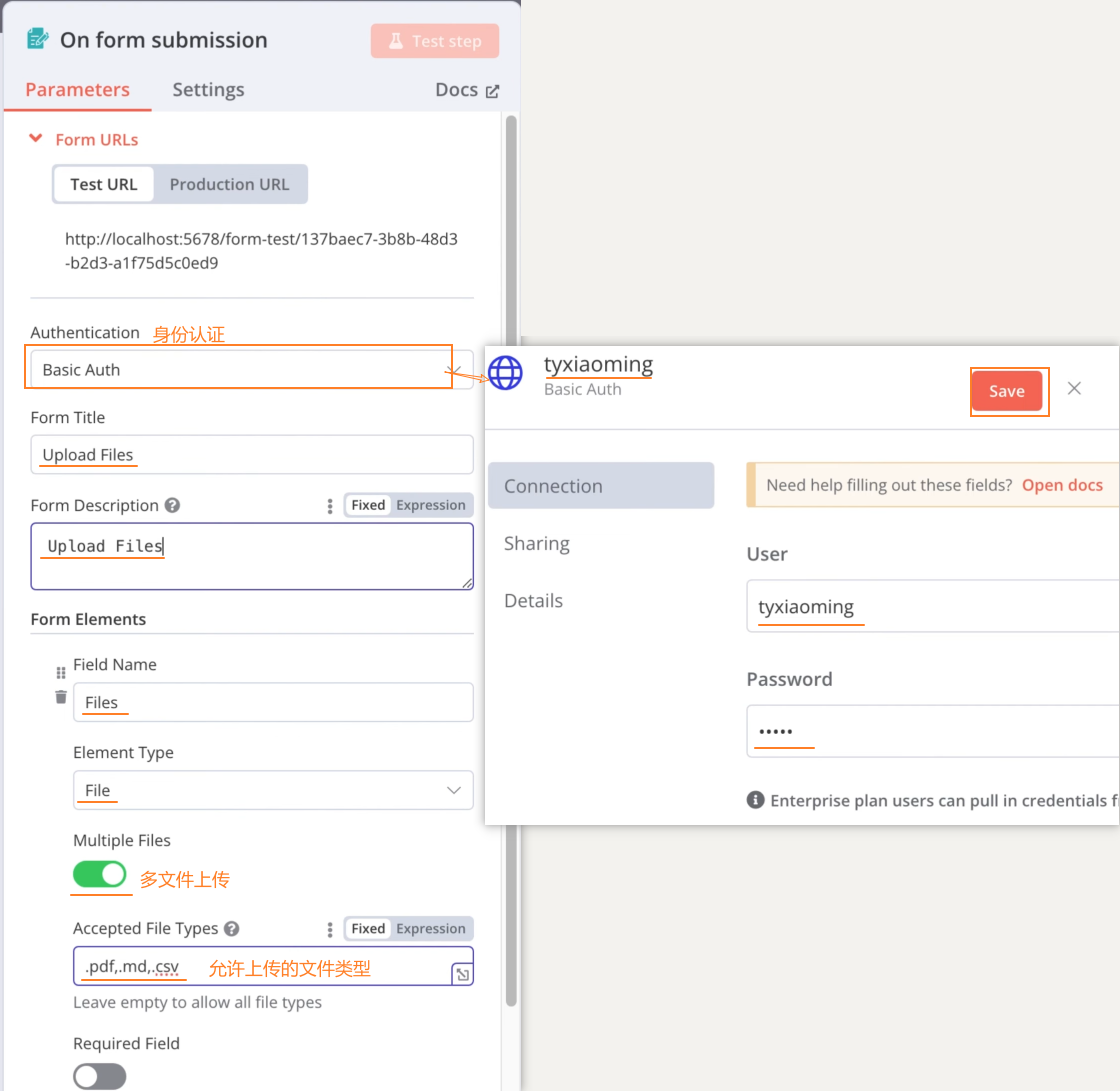
表单提交节点:
添加向量数据库节点:

pinecone 设置:
注册 pinecone 账号,创建并获取 API key
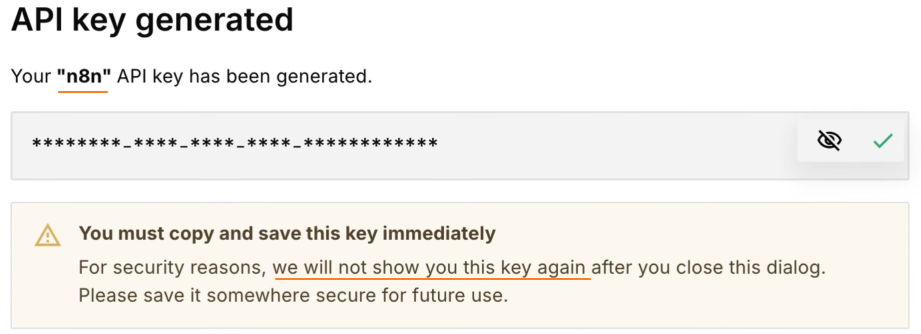
创建 index:
Database - Indexes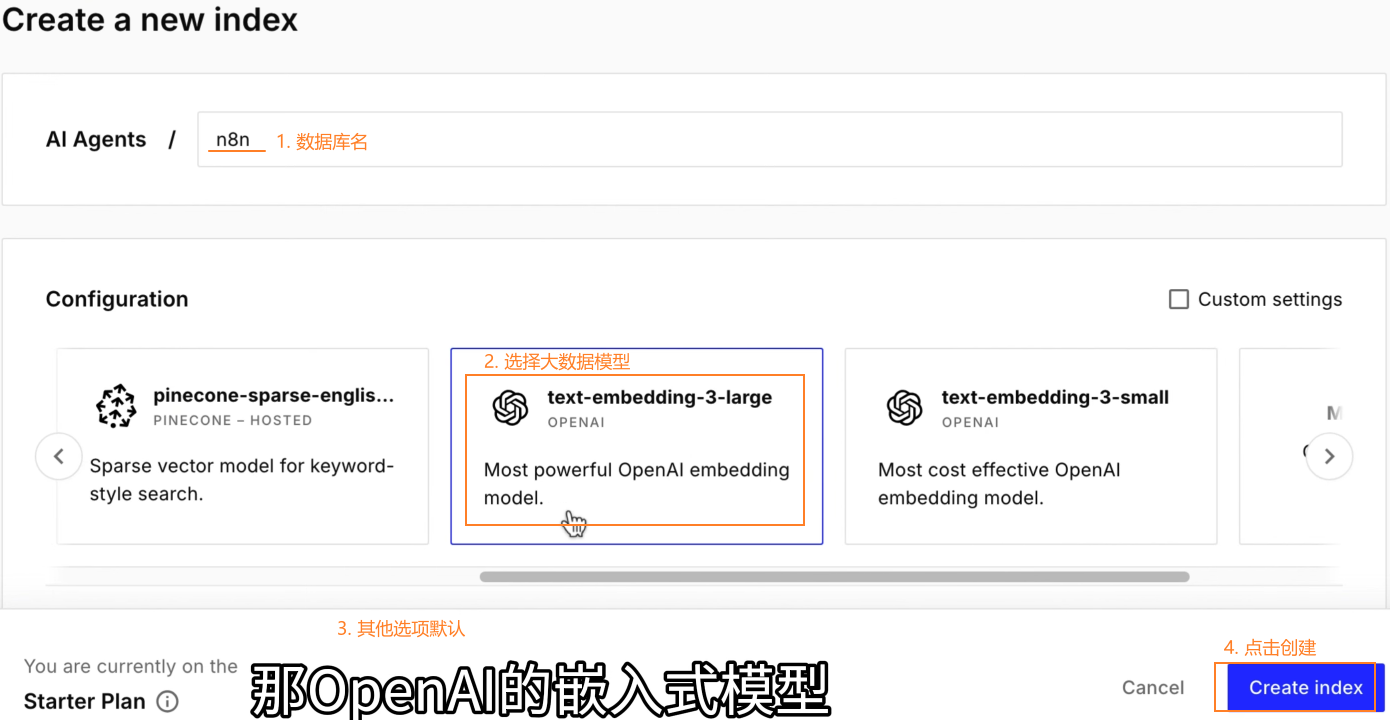
创建完成:
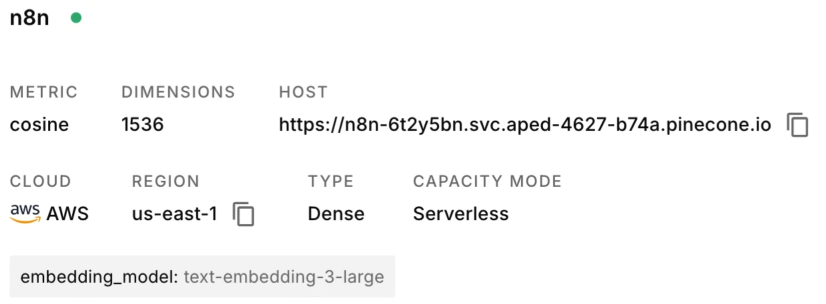
N8N 节点配置:
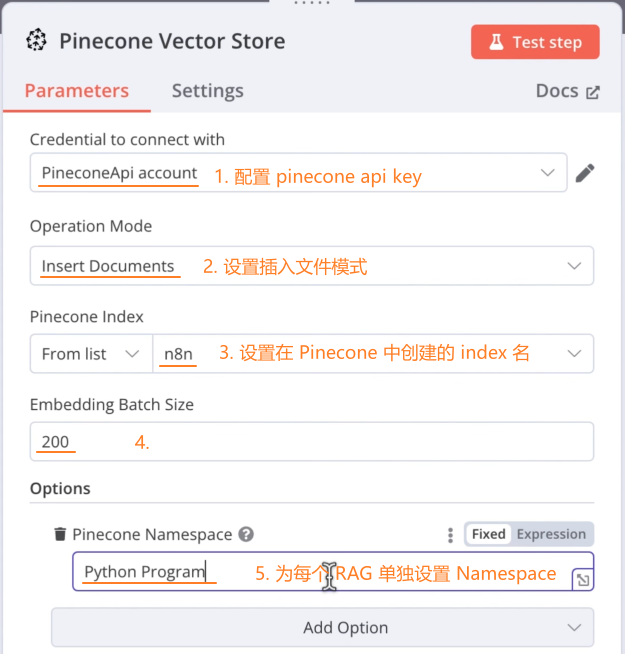
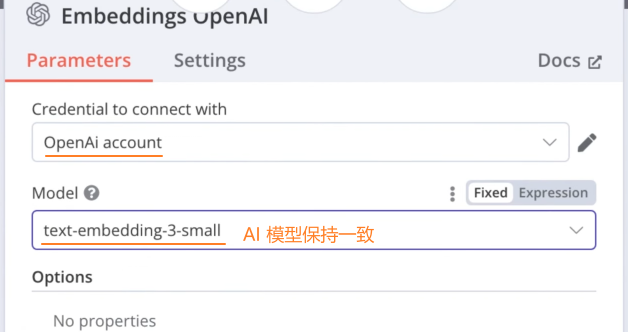
为向量数据库节点配置大模型节点:和pinecone 的 index 中使用的大模型保持一致
openai 配置:
注册 openai 账号(卡住:需要干净的IP节点):
添加支付方式(卡住:需要支付卡):
Settings - Billing
充值:最少 $5

创建 API key:
API keys - <Create new secret key>
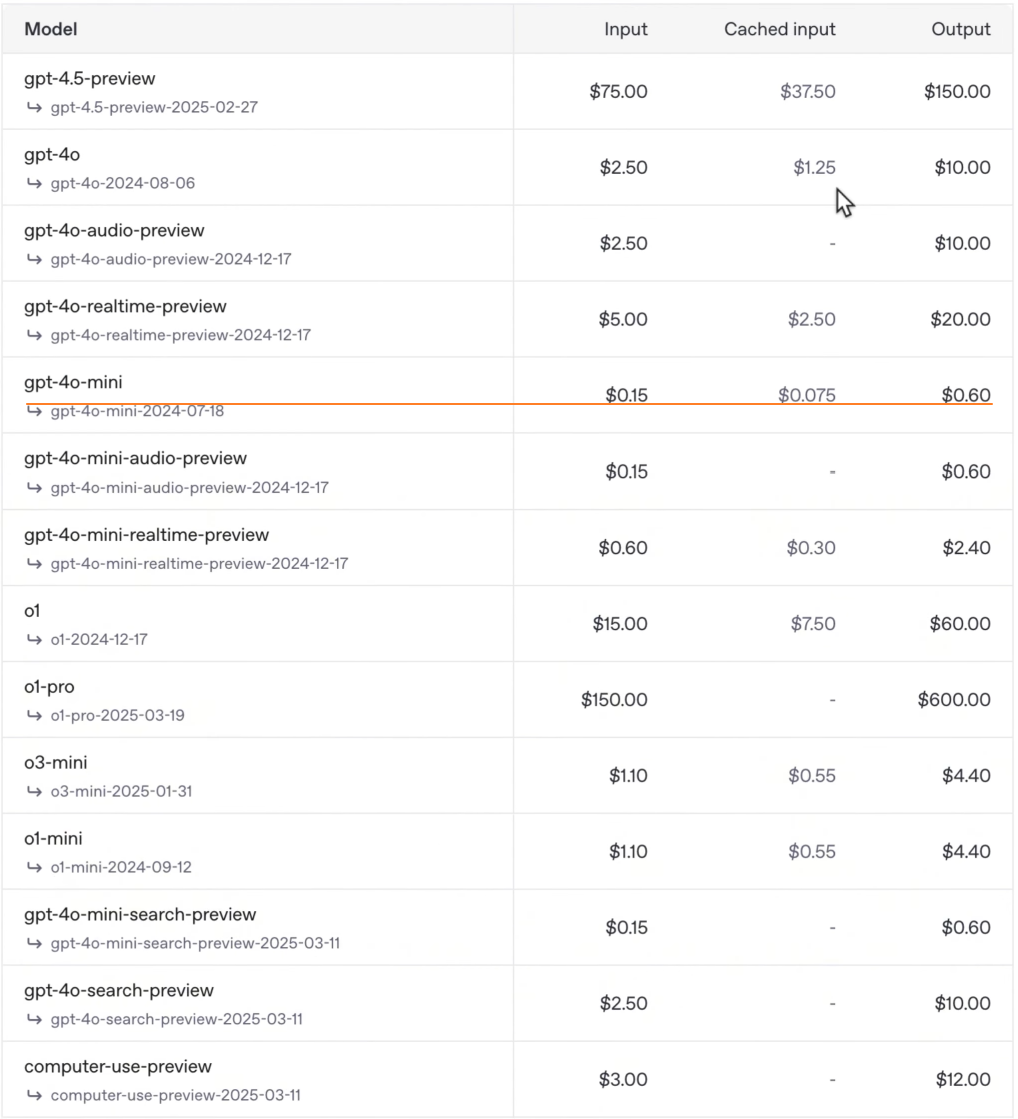
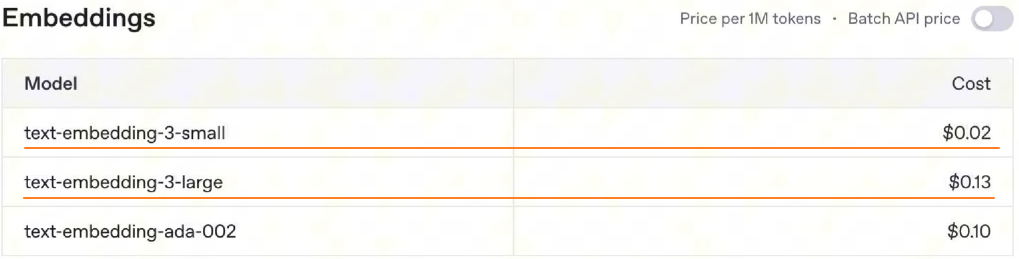
GPT 模型价格:
N8N 配置:
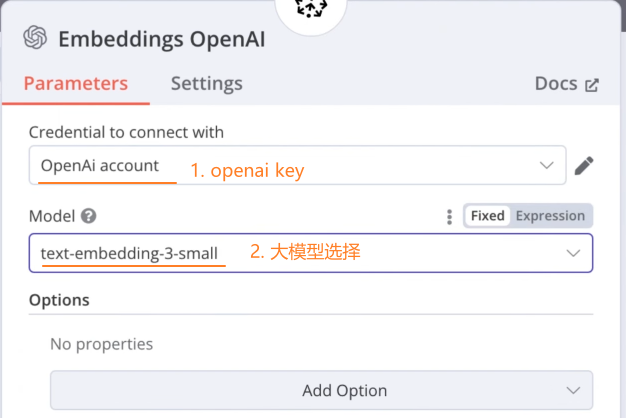
Default Data Loader 节点:
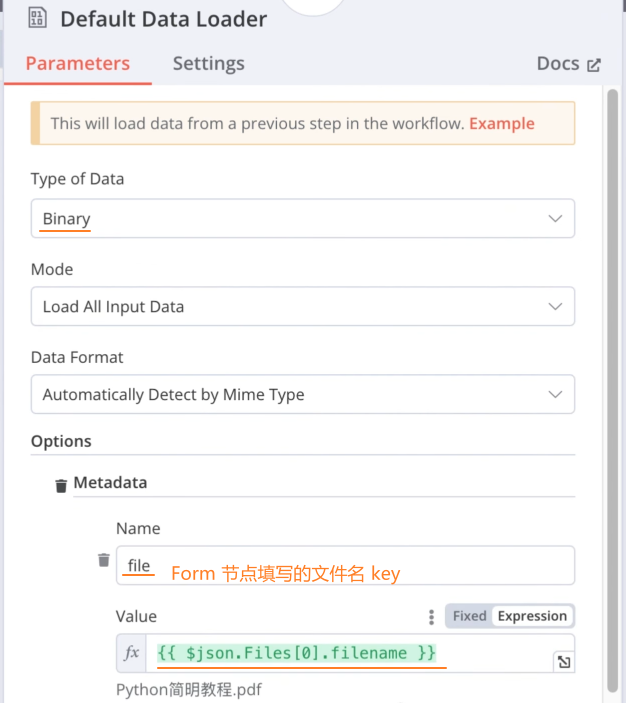
Recursive Character Text Splitter 节点:
工作流全景:
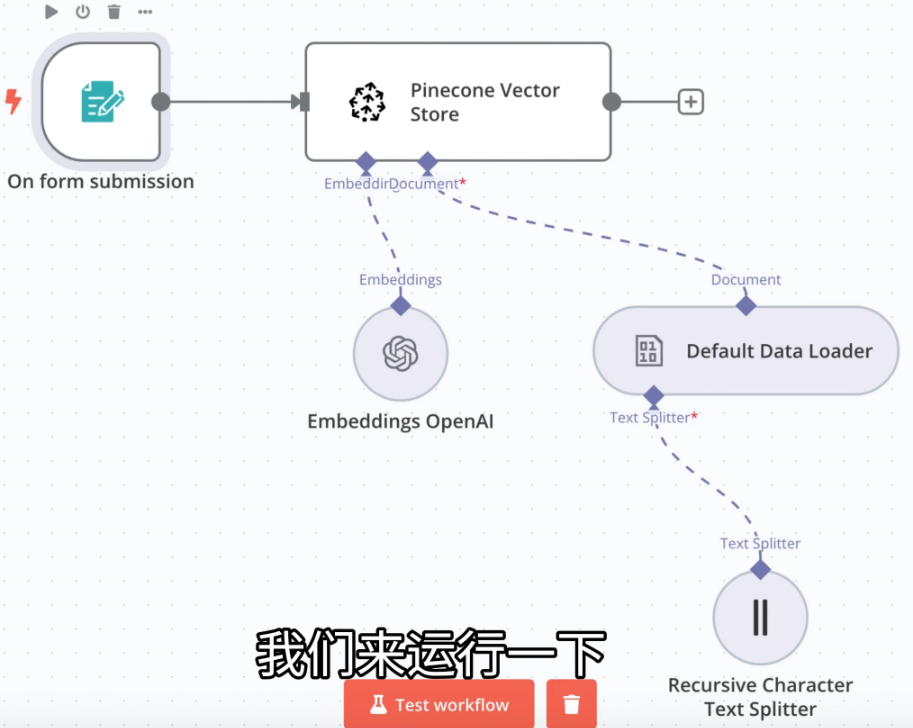
重命名工作流并下载到本地
方式二:crawl4ai爬取
安装crawl4ai
拉取 docker 镜像:
shdocker pull unclecode/crawl4ai:all-amd64查看当前镜像:
shdocker images启动 crawl4ai 镜像:
shdocker run -it \ -p 11235:11235 \ -e CRAWL4AI_API_TOKEN=12345 \ --name crawl4ai \ --shm-size=3g \ unclecode/crawl4ai:all-amd64验证启动成功:访问以下网址:
jshttp://127.0.0.1:11235 // 注意:需要将 0.0.0.0 IP替换成 127.0.0.1
获取网站sitemap
方式一:访问网站域名后的
/sitemap.xml页面shhttps://docs.crawl4ai.com/sitemap.xml方式二:对于不支持 sitemap 的网站,可以通过 xml-sitemaps 网站生成 sitemap

N8N工作流
添加触发节点
on chat message添加节点
HTTP Request: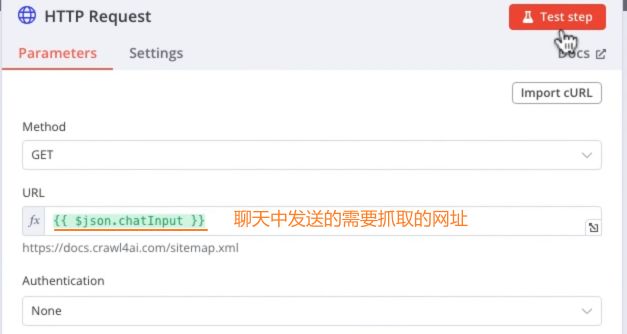
添加
XML节点:将XML格式内容转成JSON格式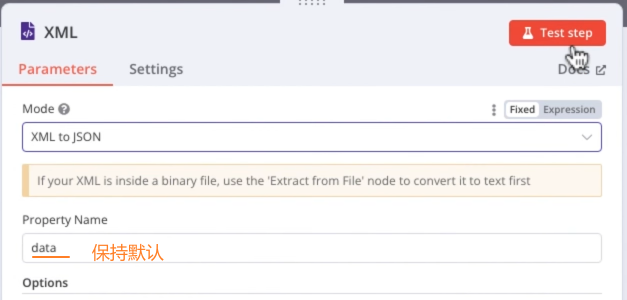
添加
Split Out节点:将JSON格式的内容切分成一个个URL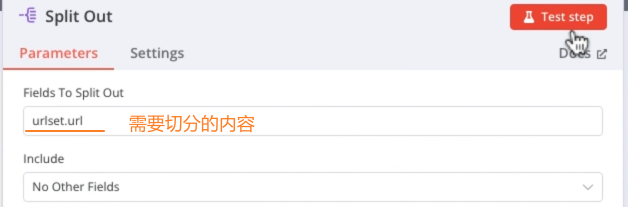
添加
Limit节点:限制一次抓取的个数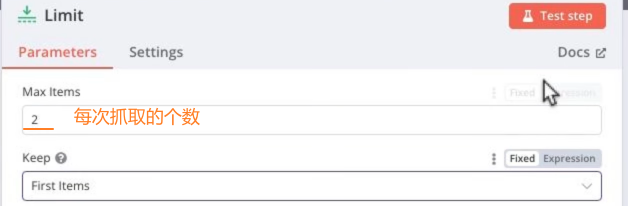
添加
Loop Over Items节点:循环处理每个URL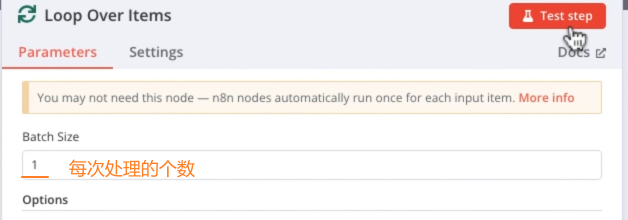
替换
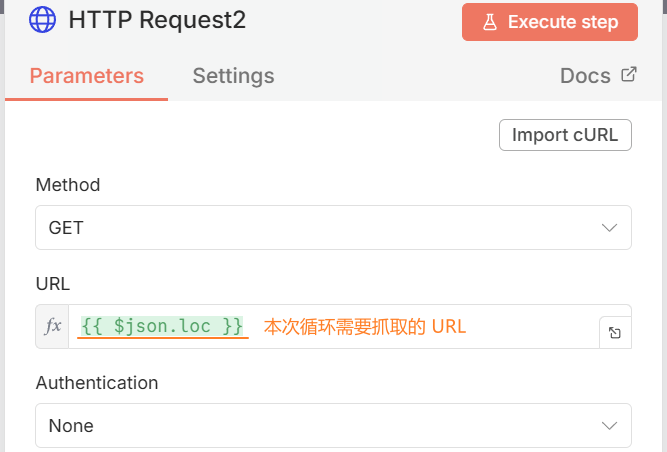
Repeat Me节点为HTTP Request节点:每循环一次抓取一次网页
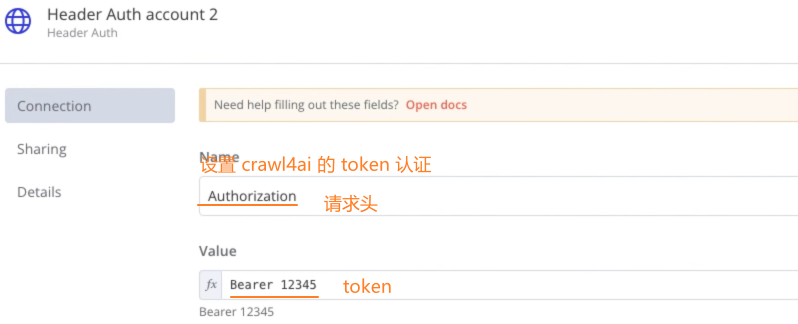
设置 crawl4ai 的 token 凭证(token是在docker安装 crawl4ai 镜像时设置的)
设置
HTTP Request节点,执行 Test,会返回一个task_id用于之后的 HTTP 抓取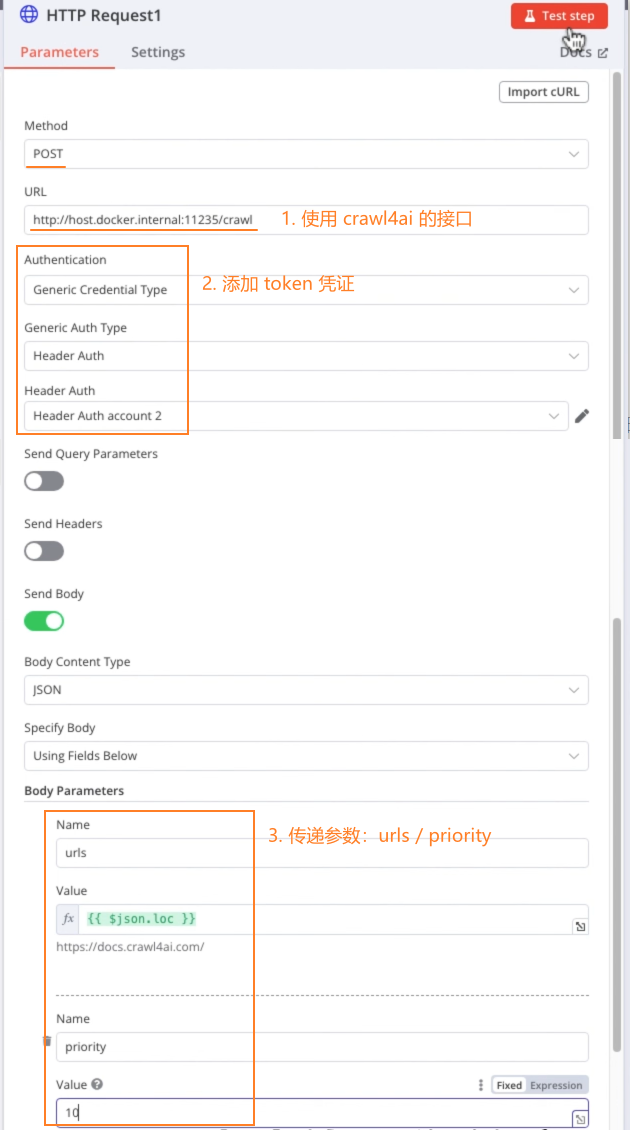
添加
Wait节点:每次抓取中间等待几秒,防止引发网站反扒策略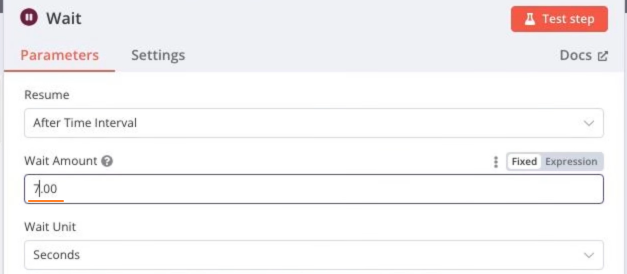
添加
HTTP Request节点:使用以下 crawl4ai API 执行抓取任务:sh# http://host.docker.internal:11235/crawl # 1. 获取 task_id http://host.docker.internal:11235/task/<task_id> # 2. 根据 task_id 执行实际抓取任务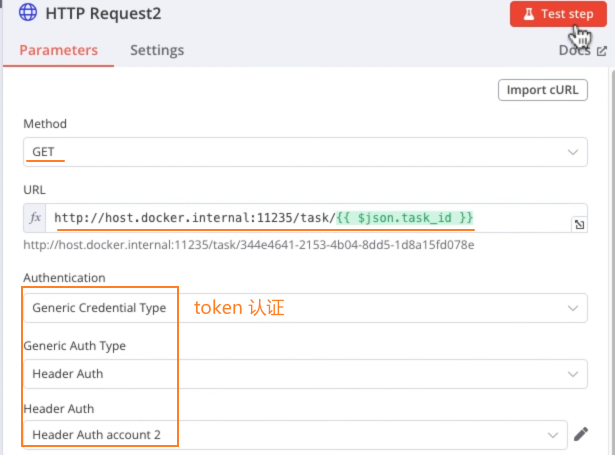
添加
If节点:根据stauts属性值判断抓取是否成功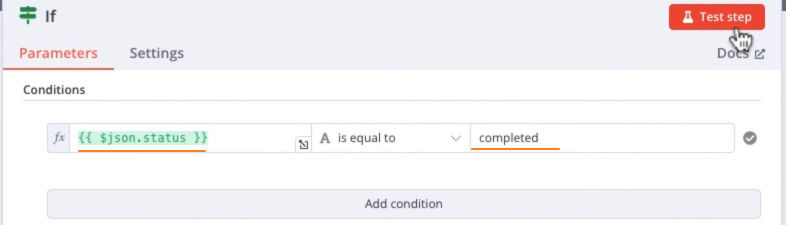
成功:添加
AI Agent节点:自定义 AI 提示词text角色设定: 你是一名信息结构化和知识库开发的专家,请始终保持专业态度。你的任务是将 markdown 数据整理为适合 LLM 驱动的 RAG 知识库的结构化、易读格式。 任务要求: 1. 内容解析 - 识别 markdown 数据中的关键内容和主要结构。 2. 结构化整理 - 以清晰的标题和分层逻辑组织信息,使其易于检索和理解。 - 保留所有可能对回答用户查询有价值的细节。 3. 创建 FAQ(如适用) - 根据内容提炼出常见问题,并提供清晰、直接的解答。 4. 提升可读性 - 采用项目符号、编号列表、段落分隔等格式优化排版,使内容更直观。 5. 优化输出 - 严格去除 AI 生成的附加说明,仅保留清理后的核心数据 响应规则: 1. 完整性: 确保所有相关信息完整保留,避免丢失对搜索和理解有价值的内容。 2. 精准性: FAQ 需紧密围绕内容,确保清晰、简洁且符合用户需求。 3. 结构优化: 确保最终输出便于分块存储、向量化处理,并支持高效检索。 数据输入: <markdown>XXX</markdown>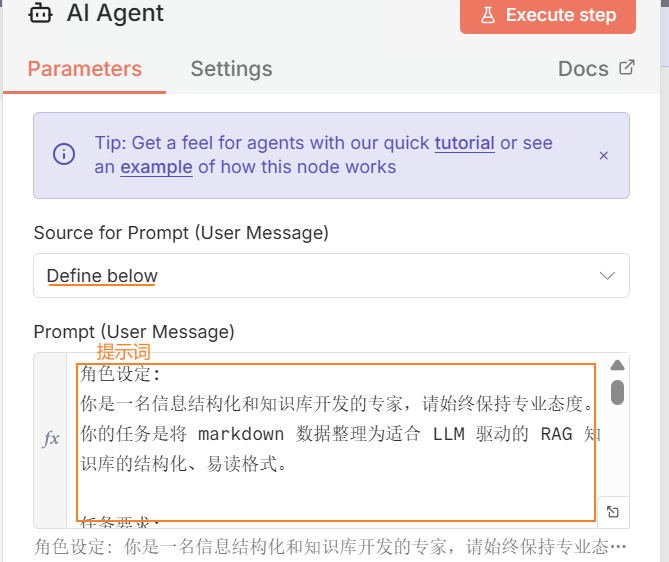
失败:添加
Edit Fields节点:自定义task_id属性,用于重新抓取网页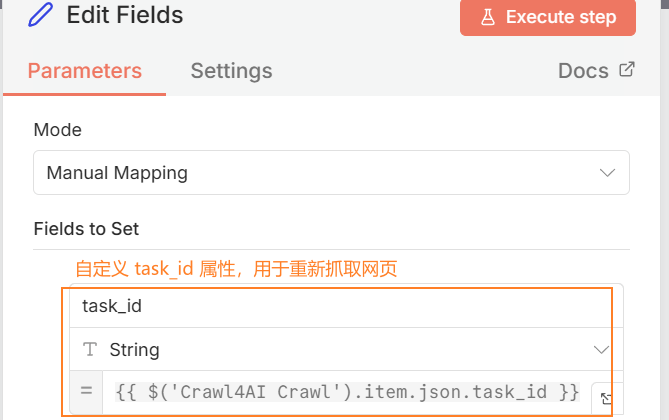
添加
Convert to File节点:保存抓取的数据到本地文件中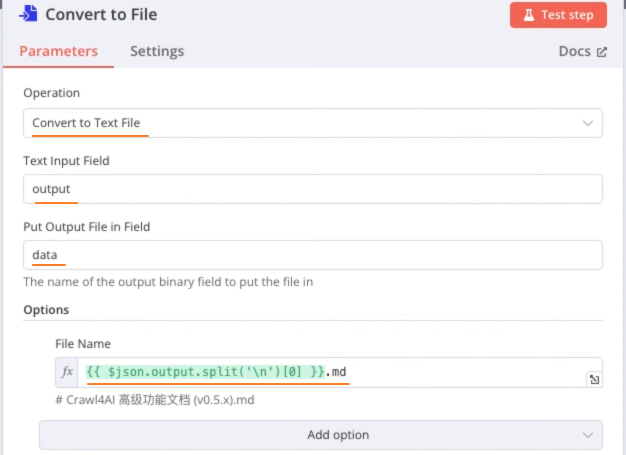
添加
Read/Write Files from Disk节点:保存生成的文件到本地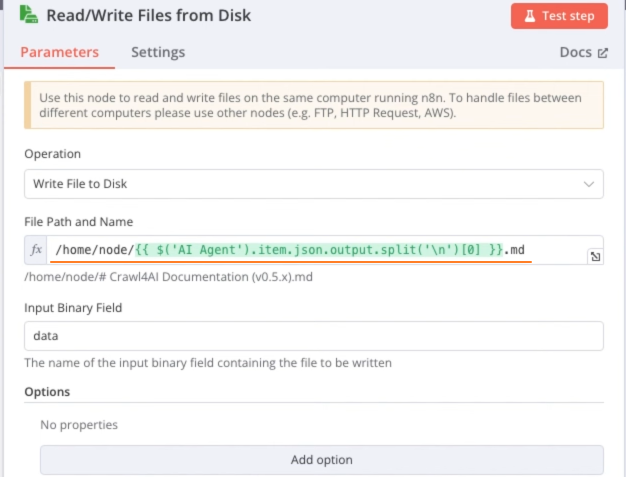
大模型搭配知识库
大模型搭配知识库:
思路:
On Chat Message 节点:保持默认表单填写
AI Agent 节点:
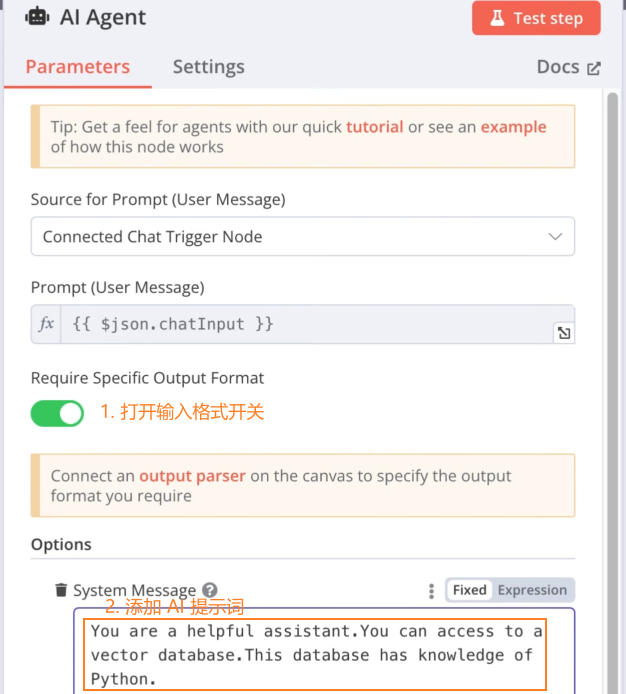
添加 AI 模型节点:
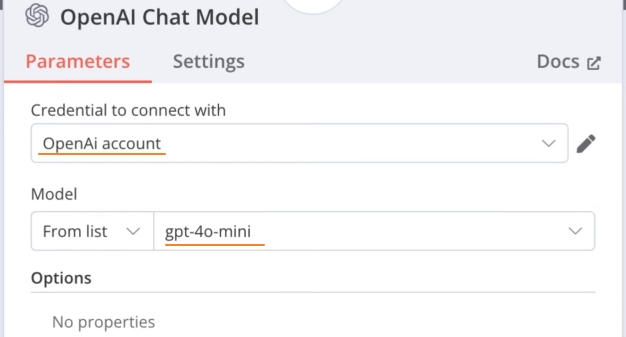
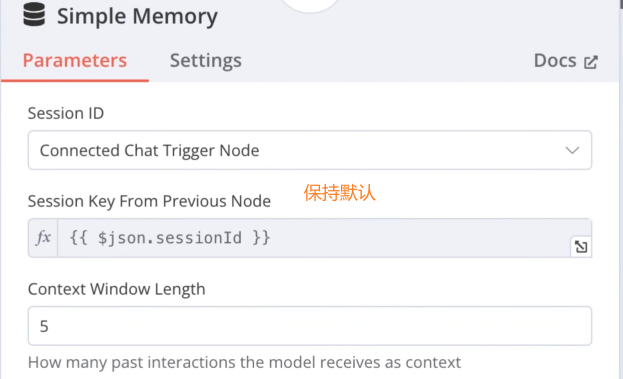
添加 Simple Memory 节点:
添加 Answer questions with a vector store 节点:
注意:
Data Name:不能有空格,可以改成Python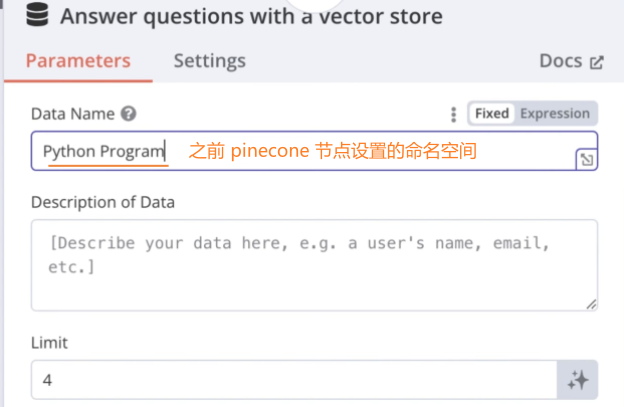
添加 Pinecone Vector Store 节点:
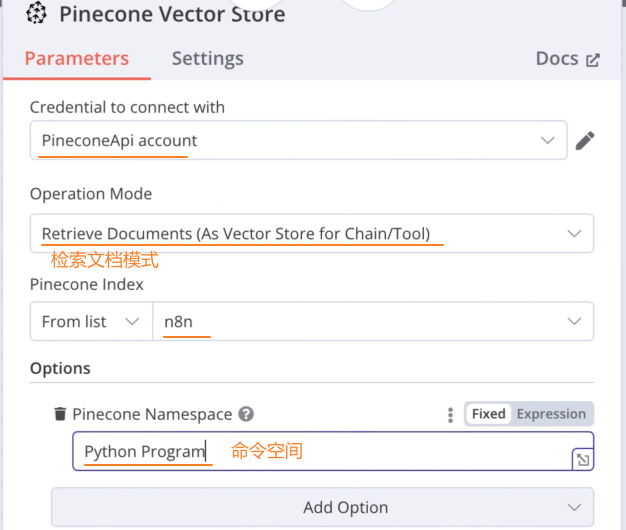
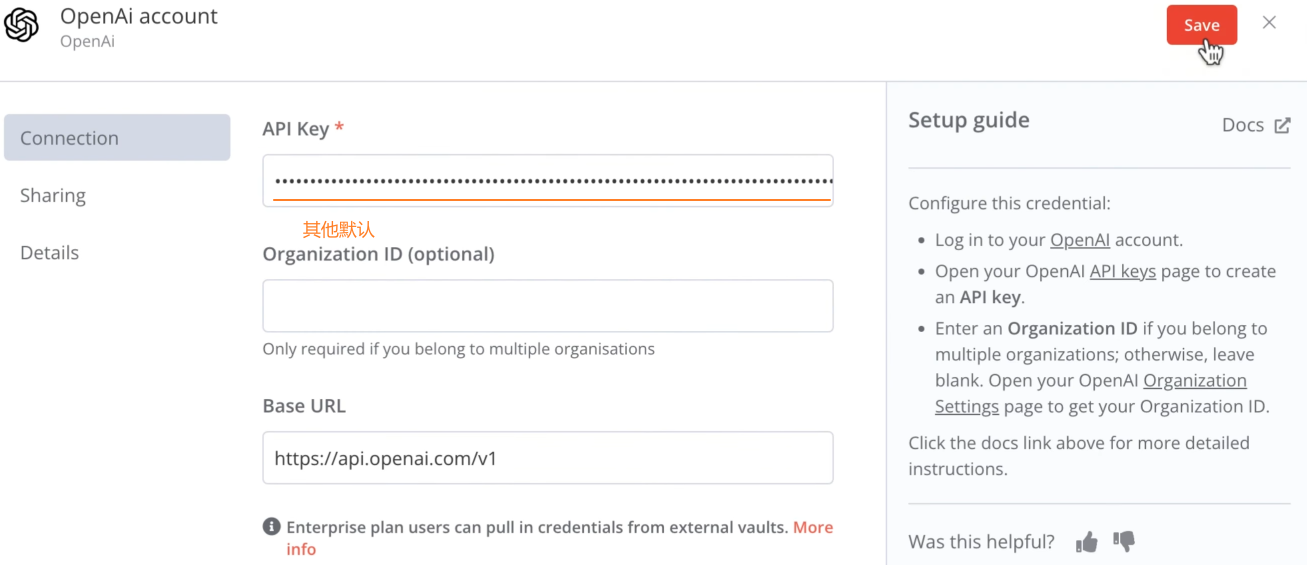
添加 Embeddings OpenAI 节点:和之前的AI 模型保持一致
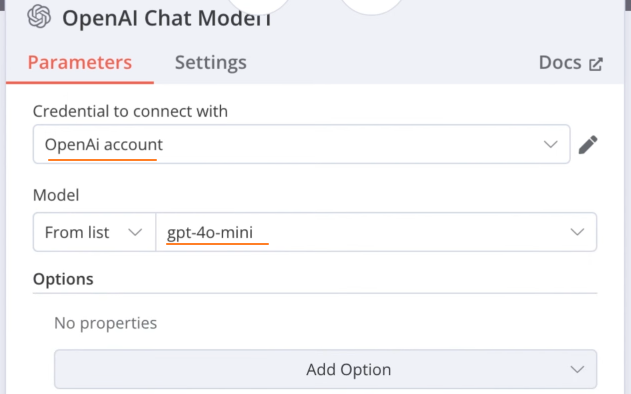
给 Tool 节点添加 AI 模型:
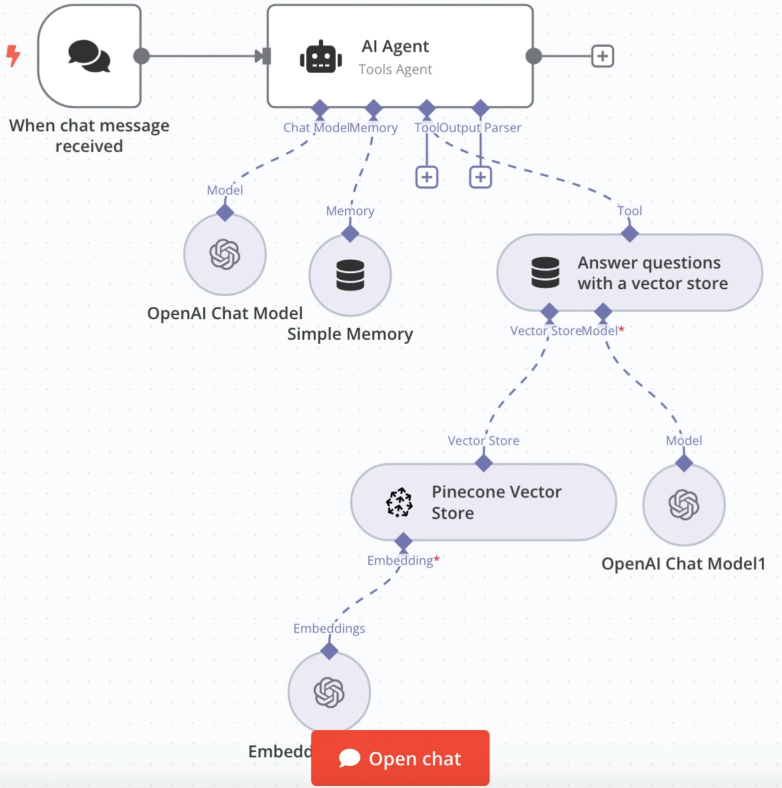
工作流全景图:
网站嵌入RAG
网站嵌入RAG:
思路:RAG系统会对外生成一个 API 接口(聊天框),通过依赖包 @n8n/chat 可以将该接口放在网页的指定位置,页面发生对话后 N8N 会启动工作流,调用 RAG 系统回答用户的问题。
N8N 设置
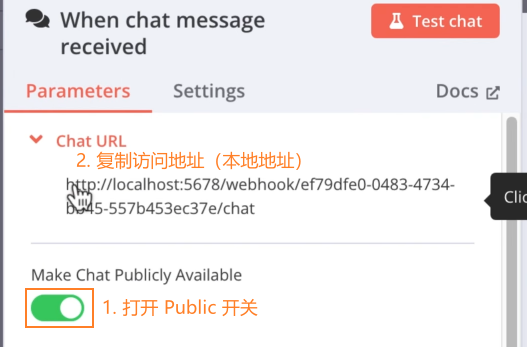
Public 访问:点击初始的 chat 节点,开启 Public 访问,复制 URL 访问,点击 Active 启动工作流后就可以访问了
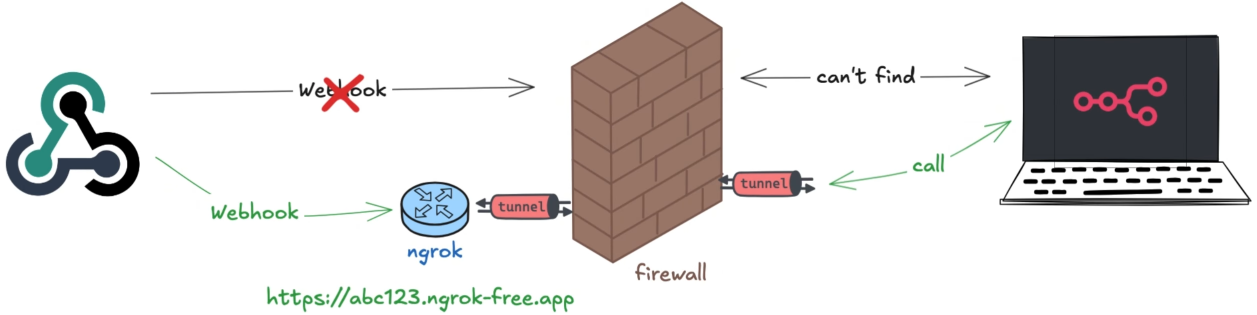
注意:此处的 URL 是本地地址,只能本机访问,如果要在线访问,需要设置隧道
搭建隧道
方式一:ngrok
ngrok 地址:https://ngrok.com/
原理图:
安装 ngrok CLI:
执行安装命令:
sh# Mac brew install ngrok # Debian Linux curl -sSL https://ngrok-agent.s3.amazonaws.com/ngrok.asc \ | sudo tee /etc/apt/trusted.gpg.d/ngrok.asc >/dev/null \ && echo "deb https://ngrok-agent.s3.amazonaws.com buster main" \ | sudo tee /etc/apt/sources.list.d/ngrok.list \ && sudo apt update \ && sudo apt install ngrok配置 ngrok token:
sh# $YOUR_TOKEN:注册 ngrok 后获取的 ngrok config add-authtoken $YOUR_TOKEN部署 N8N 项目上线:
shngrok http http://localhost:5678 # 5678端口是 N8N 服务的端口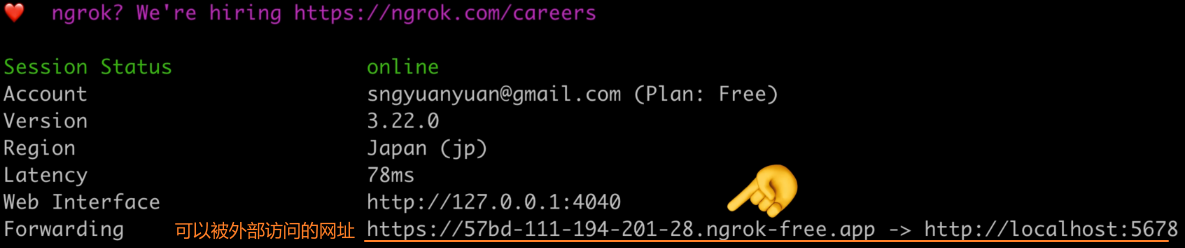
重启 N8N,设置 webhook 网址:
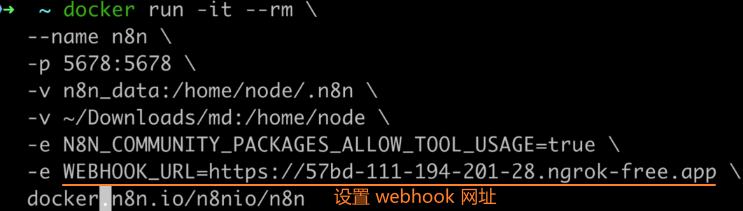
此时设置 N8N 为 Public 访问时,给出的 URL 就是一个在线网址
注意:ngrok 服务不能停止,否则该 URL 会失效
方式二:CloudFlare【
工作流嵌入网站
依赖包:@n8n/chat
在网站指定的位置嵌入以下脚本:(此处为 CDN 嵌入,其他方式访问依赖包查看)
<link href="https://cdn.jsdelivr.net/npm/@n8n/chat/dist/style.css" rel="stylesheet" />
<script type="module">
import { createChat } from 'https://cdn.jsdelivr.net/npm/@n8n/chat/dist/chat.bundle.es.js';
createChat({
webhookUrl: 'YOUR_PRODUCTION_WEBHOOK_URL' // webhookUrl 就是上面给出的 URL 在线网址
});
</script>Telegram嵌入RAG
Telegram嵌入RAG:
思路:
替换初始 Chat 节点为 Telegram 节点:选择
on message事件添加 Telegram 凭证:
通过 BotFather 机器人新建机器人:
1、点击
/newbot命令新建机器人,输入机器人名称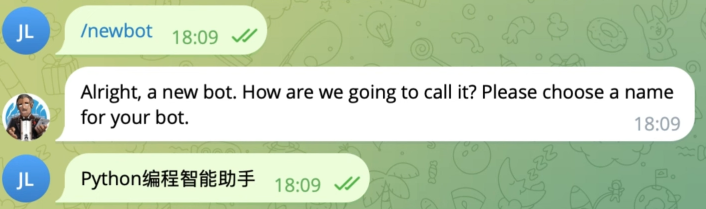
2、输入 username(必须以
bot结尾),此时就生成了需要的 token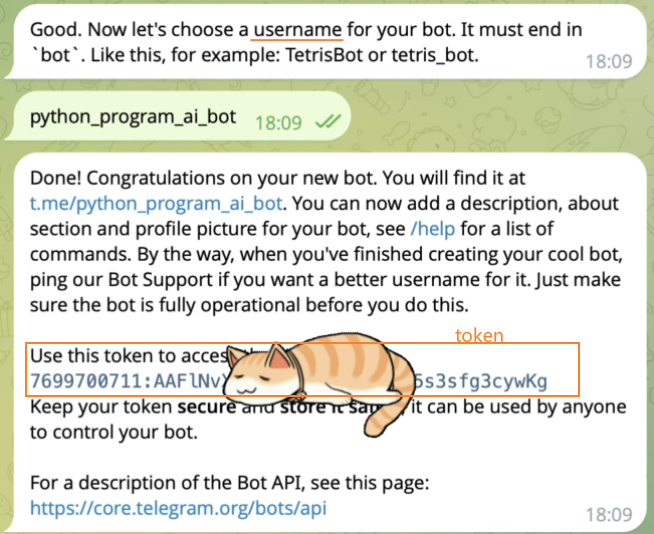
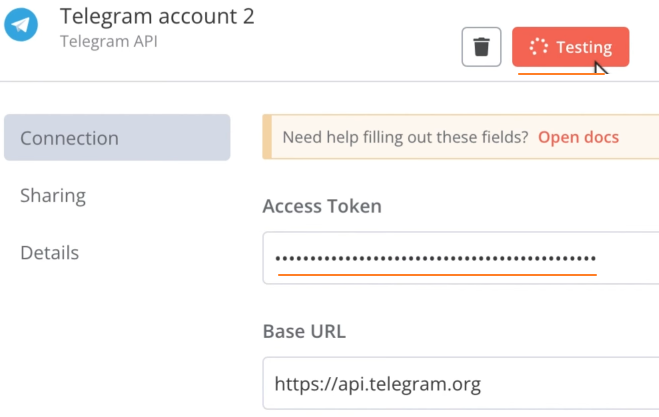
3、添加 token 到 Telegram 节点
选择添加的凭证:
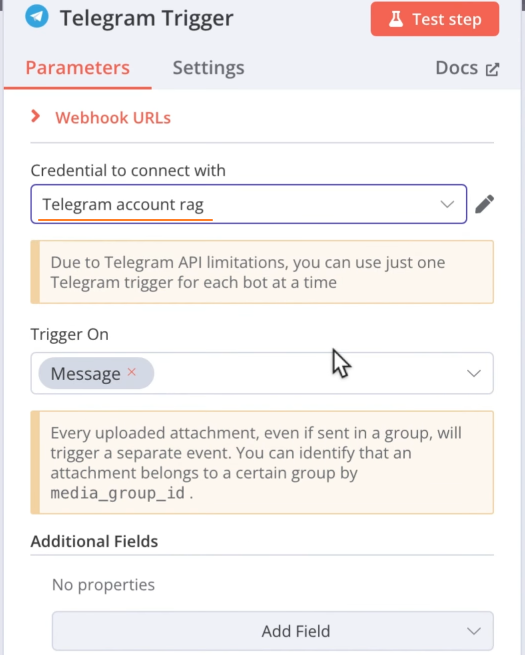
修改 AI Agent 节点的 Simple Memeory 节点的触发方式:
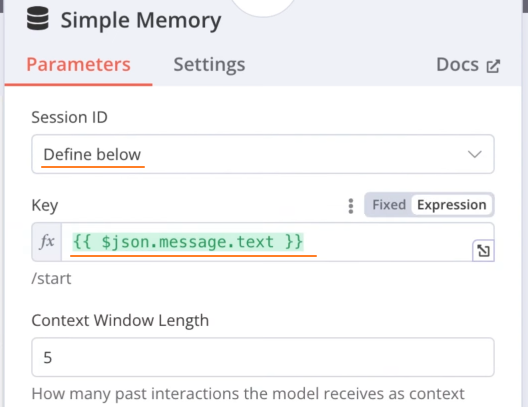
添加发生 Telegram 消息的节点:选择
Send a text message事件获取
chat_id:搜索get_bot_id机器人并启用,输入/my_id命令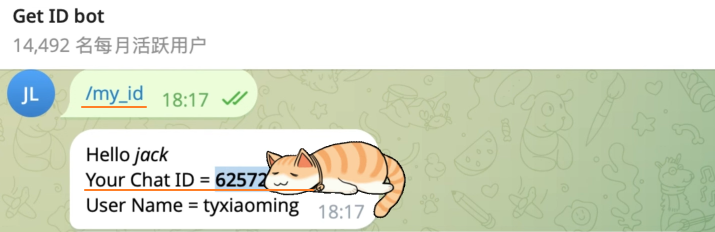
填写表单:
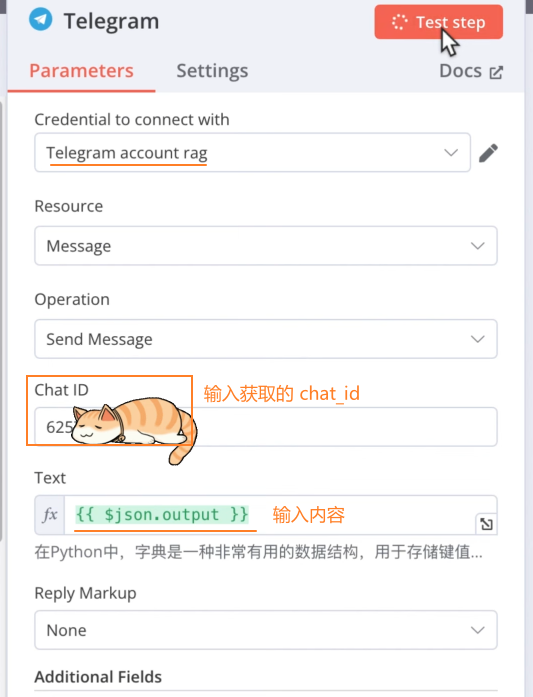
工作流全景图:
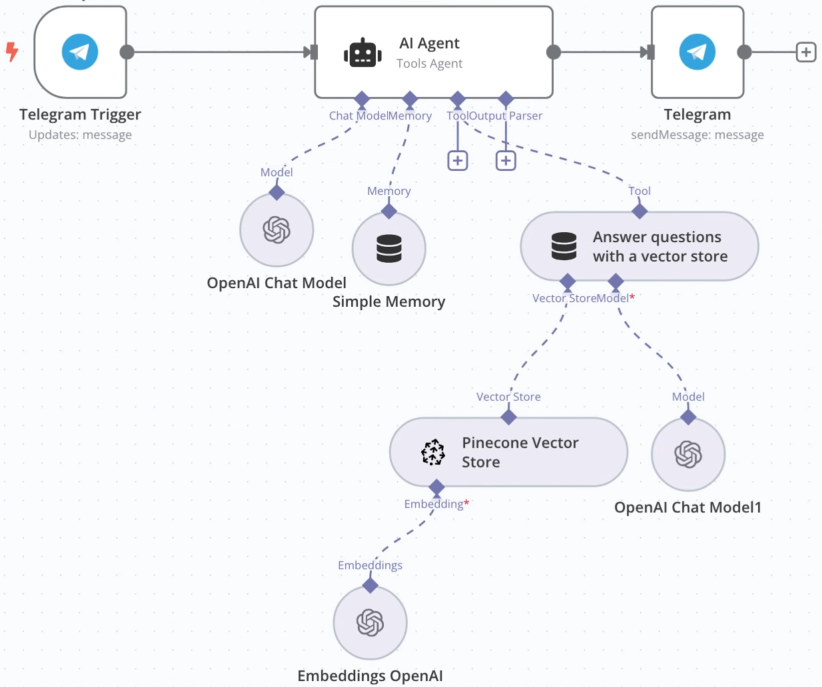
测试:在 Telegram 中创建的机器人中发送消息,就会触发该工作流